PRISM AI Observability
AI observability built for compliance teams.
Every LLM call captured, scored, and stored with PII scrubbed before it lands in your database. Regulator-ready exports in under 60 seconds.
- #4821Credit Risk Query1.3s5/5PII redacted
- #4820Underwriting Decision0.9s3/5Drift detected
- #4819Policy Lookup0.4s5/5Grounded
Audit pack ready
47 traces · 60s export
PRISM
Know what you're shipping before you ship it
Model audits give you a structured review of model behavior, risk profile, and readiness for production, before deployment, not after incidents.
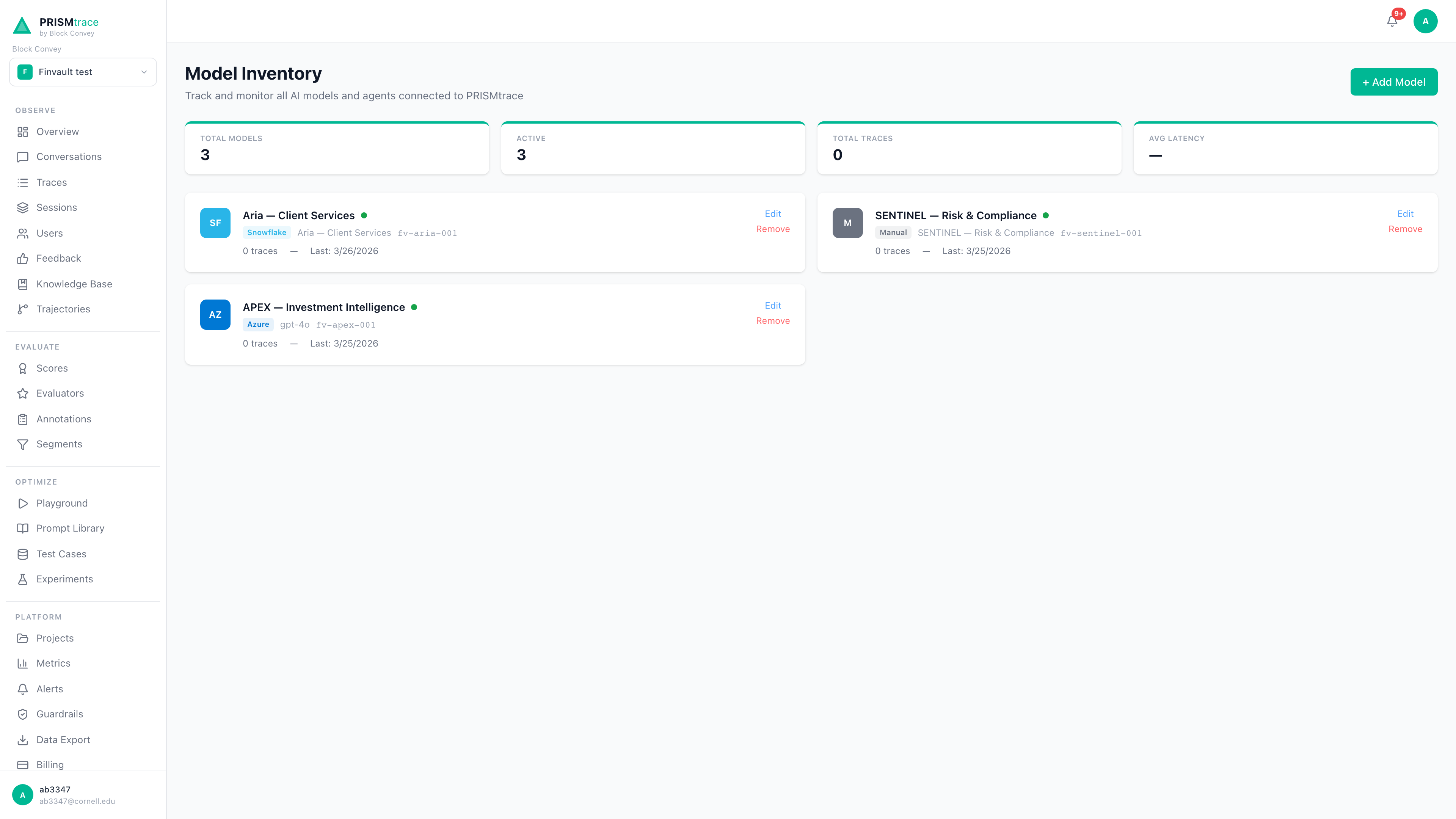
- Model inventory: every model in use with provider, version, and data flow
- Behavioral testing against your evaluation datasets and rubrics
- Side-by-side comparison across candidate models and versions
- Audit report suitable for risk committees and regulatory submissions
The problem
Teams adopt new models, or new versions of existing models, based on benchmarks, blog posts, and quick experiments. But benchmark performance does not predict production behavior. A model that scores well on general tasks may hallucinate on your domain, handle edge cases poorly, or behave differently under load. You need a structured process to evaluate model fitness for your specific use case before committing production traffic.
Capabilities
What you get with PRISM
Model inventory
Catalog every model in use across your organization: provider, version, deployment context, data flow, and downstream consumers. Know what's running where.
Behavioral testing
Run your evaluation datasets against the model and review scores across accuracy, relevance, completeness, safety, and efficiency, using the same evaluators that monitor production.
Risk assessment
Identify failure modes specific to your domain: hallucination on terminology, inconsistent edge-case handling, prompt sensitivity, and cost / latency under realistic load.
Model comparison
Side-by-side scoring of candidate models (GPT-4o vs. Claude Sonnet vs. fine-tuned variant) against the same dataset and evaluators. Model selection becomes evidence-based.
Audit documentation
Structured report covering model identity, intended use, evaluation results, identified risks, and deployment recommendations.
How it works
From instrumentation to evidence
- 1
Catalog the model inventory
Record every model in use across the organization: provider, version, deployment context, data flow, and downstream consumers.
- 2
Run behavioral tests
Run your evaluation datasets against the model using the same evaluators that monitor production: accuracy, relevance, completeness, safety, efficiency.
- 3
Assess risk and compare
Identify failure modes specific to your domain and run side-by-side comparison of candidate models against the same dataset and evaluators.
- 4
Document the decision
Generate a structured audit report covering model identity, intended use, evaluation results, identified risks, and deployment recommendations.
What teams use it for
In production, every day
Adopting a new model
Run the audit before pointing production traffic at a new model or provider, with side-by-side scoring against current incumbents.
Version upgrades
Before upgrading to a new model version, replay evaluation datasets through the candidate to catch regressions on domain-specific behavior.
Quarterly compliance cycle
Run audits on a quarterly or annual cycle for regulatory compliance, or when production scores show unexplained drift.
Audit coverage
What a model audit covers
Model inventory
Catalog every model in use across your organization: provider, version, deployment context, data flow, and downstream consumers.
Behavioral testing
Run your evaluation datasets against the model and review scores across the five evaluator dimensions used in production.
Risk assessment
Identify failure modes specific to your domain: hallucination on terminology, edge-case handling, prompt sensitivity, cost and latency under load.
Comparison
Side-by-side scoring of candidate models against the same dataset and evaluators, so model selection is evidence-based.
Deliverable
Audit report
A structured audit report covering model identity, intended use, evaluation results, identified risks, and deployment recommendations, suitable for internal review boards, risk committees, and regulatory submissions.
Regulatory alignment
Built for Model Risk, CROs, ML Engineering Leads
Related capabilities
LLM Observability: Trace Logging Built for Compliance
Structured traces give you the full story of what your AI said, why it said it, how long it took, and what it cost.
LLM Guardrails: PII Redaction and Prompt Injection Blocking
Real-time detection and enforcement for PII, PHI, prompt injection, content policy violations, and off-topic responses, scoped per agent, per project, per knowledge base.
LLM Evaluations: Five-Dimension Automated Quality Scoring
Define quality rubrics, score every interaction, and catch regressions before users do, with automated evaluators that run on every trace or on a schedule you control.
PRISMX: AI DLP for Employees Using ChatGPT, Claude, Gemini
PRISMX enforces data loss prevention policy in the browser, before prompts and uploads reach third-party AI services. Signed policy, real-time enforcement, audit-grade events.
Start tracing in 5 minutes
One SDK. Five minutes. Full audit trails, PII redaction, and guardrail enforcement, from day one.